UPDATE, 2024-04-09: I’ve found out that I didn’t filter out the dead and deleted stories and comments from my analysis. I’ve updated the analysis accordingly. While there are changes in the numbers and figures, the patterns and observations stand. I’ve also removed one table related to the second analysis (HN as a competitive platform), because: 1) it was confusing, 2) it didn’t add new information, 3) and with the new data, the categorization bins needed rethinking.
What is the status of the ~18-year-old HN?
Instead of reading the stories, why not just dismantle HN and look under the hood?
I love HN, and it has these beautiful APIs that can expose most of HN data, so I went for it. I extracted ~40M items, plus ~0.5M users (who shared stories). This is the second large data harvesting project I do after LeMonde (1, 2, 3).
The code for this work can be found here.
The analysis of Hacker News (HN) yields three main insights:
Firstly, there’s a noticeable trend where HN is experiencing a decline in active contributors—those who comment or post stories—rather than gaining new ones.
Secondly, for those treating HN as a competitive platform where karma points serve as the score, the most effective strategy for success appears to be regular story submissions. Attempts to chase sensational news or relying on chance are less likely to yield significant karma gains.
Thirdly, while topics related to software development and business have historically been prevalent, in 2023, discussions around artificial intelligence have surged past these subjects, with business-related conversations showing a gradual decrease.
It’s important to consider that this analysis does not take into account the actual goals of HN, as they are not explicitly stated. For instance, there are ongoing debates about whether HN aims to be a platform similar to Reddit, which remain inconclusive. This analysis approaches HN as if it were any other Software as a Service (SaaS) product.
HN general stats
Hacker News (HN) comprises five types of items, with comments and stories being the most common. Here’s a breakdown:
| Type | Frequency | Percentage |
|---|---|---|
| Comment | 34.3 M | 86.8 |
| Story | 5.2 M | 13.12 |
| Job | 16.7 K | 0.04 |
| Pollopt | 14.7 K | 0.04 |
| Poll | 2 K | 0.01 |
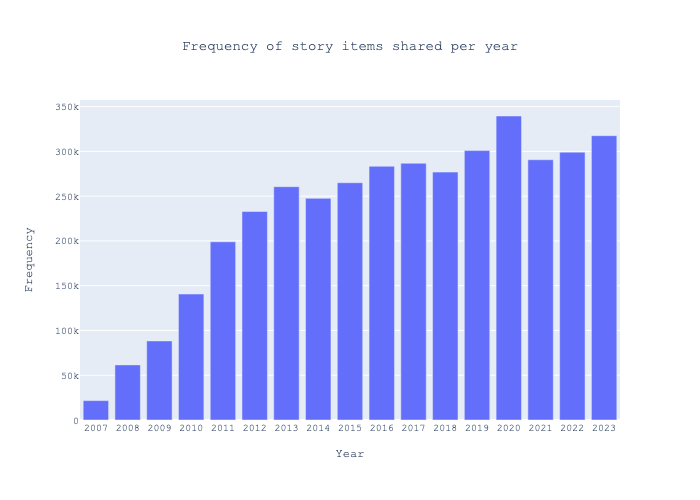
Historically, the number of stories shared on HN showed a consistent increase until 2011, after which it leveled off.
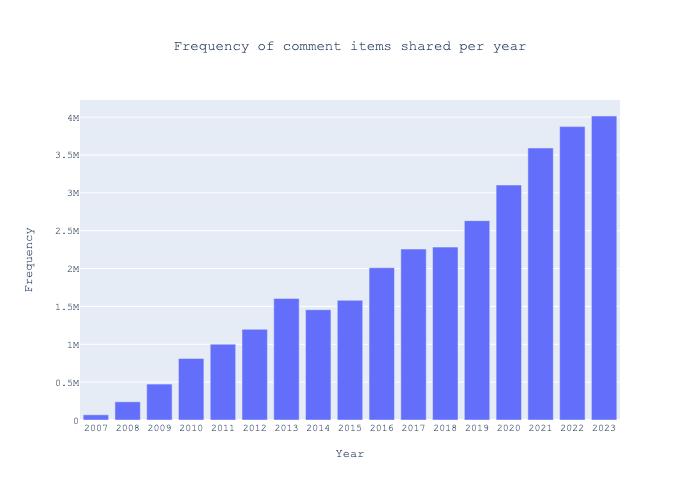
Conversely, the volume of comments has continued to rise, though the rate of growth has slowed slightly in the past three years, as observed visually.
User Engagement Trends on Hacker News
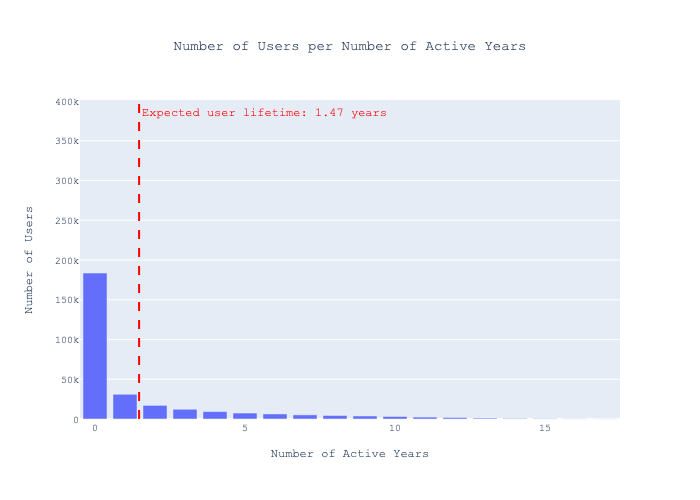
An analysis of the behavior of users who post stories on Hacker News reveals that, typically, users cease sharing stories about one year one year and half after they begin. This observation is supported by the data visualization below.
Examining the first and last activity of these users suggests a pattern indicative of user turnover. Since around 2020, the number of users ceasing to share stories has outnumbered those who start.
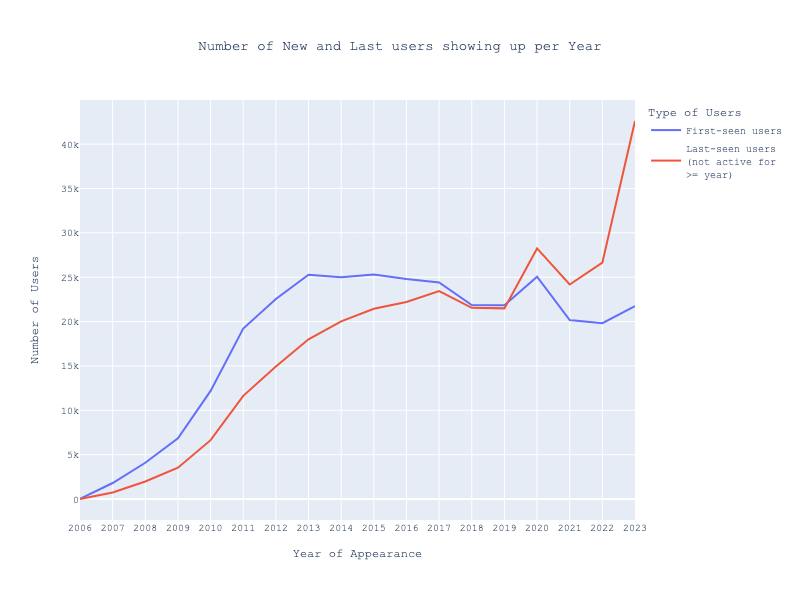
But does this trend hold true for users who primarily post comments? It appears so, as the data shows similar patterns for both story sharers and commenters.
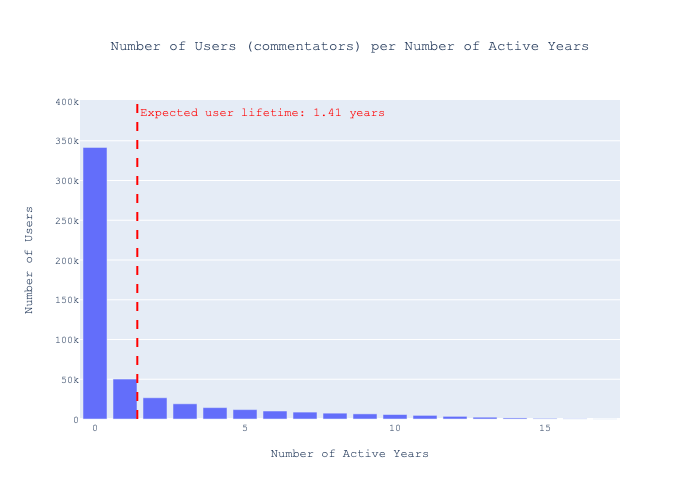
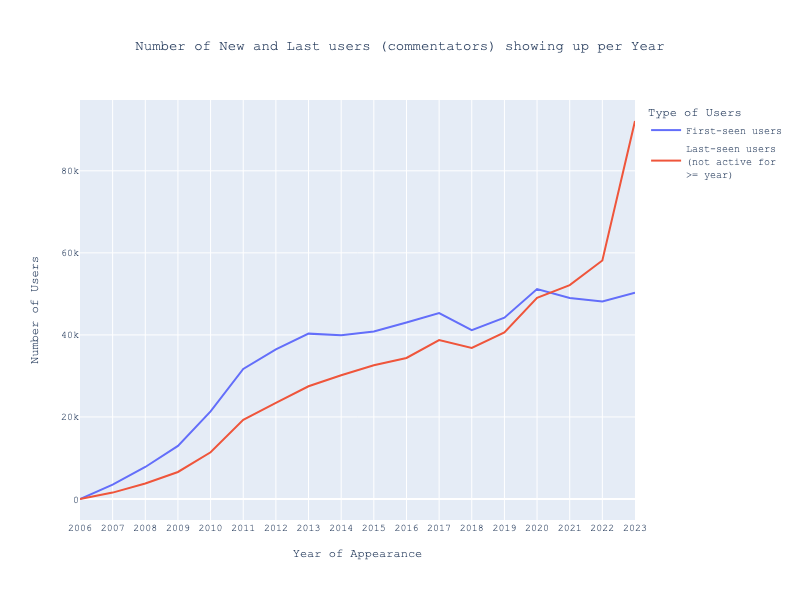
These findings suggest that Hacker News has been seeing a net loss in contributors for the past three years. Several theories could explain this trend:
- It’s possible that Hacker News has reached the limits of growth afforded by its current design.
- Users might be migrating to alternative platforms.
- The demographic of Hacker News users could be aging, with the platform struggling to attract a younger audience, a challenge similar to what Facebook has faced.
I’m eager to hear other perspectives on this matter.
Understanding Karma and Upvoting on Hacker News
For those new to Hacker News (HN), here’s a quick primer on some key elements:
- Users have profiles with a “karma” score, reflecting their reputation on the platform, which is publicly visible.
- Users can post stories and comments.
- Stories and comments can receive upvotes from other users.
- The total number of upvotes for stories is public, unlike for comments. However, users with sufficient karma can also downvote or flag content.
While accumulating karma might not be the main goal on HN, it’s interesting to explore how users can optimize their scores. Is it through sharing impactful stories or through regular contributions?
To analyze this, I’ll define the following metrics:
- Impact: Measured by the median number of upvotes a user’s stories receive. Despite potential discrepancies between perceived impact by the user and actual upvotes by readers, I’ll treat them as equivalent for this analysis.
- Consistency: Determined by the total number of stories a user has posted.
- User’s score: Instead of using karma, which has shown inconsistencies in HN data (I will discuss this in more detail laer), I’ll use the sum of upvotes received by a user’s stories as an alternative metric.
Now, examining the correlation between a user’s cumulative upvotes and their posting consistency reveals a strong relationship, with an \(R^{2}=0.796\).
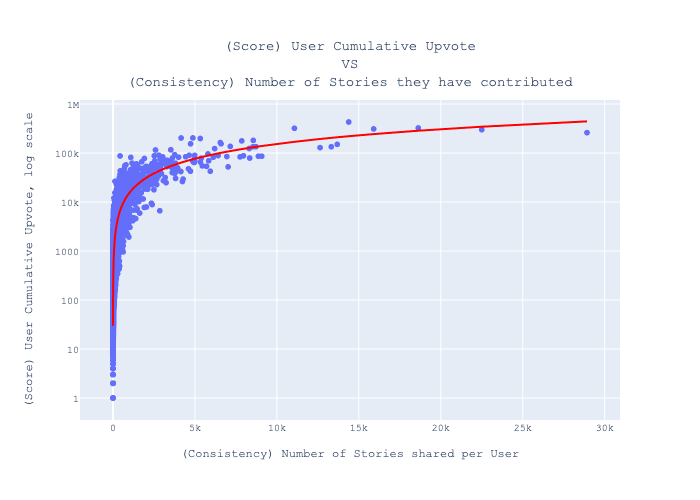
This finding suggests that the key to a high score isn’t necessarily landing viral hits, but rather consistently sharing stories.
While the previous analysis with a high \(R^2\) might suggest that consistency is key, let’s delve into whether targeting high-impact stories is a strategy employed by successful users, or if it’s more about the volume of contributions.
To investigate this, I examined the interplay between the three variables: cumulative upvotes, median upvotes per story, and the number of stories shared. The graph below illustrates this relationship.
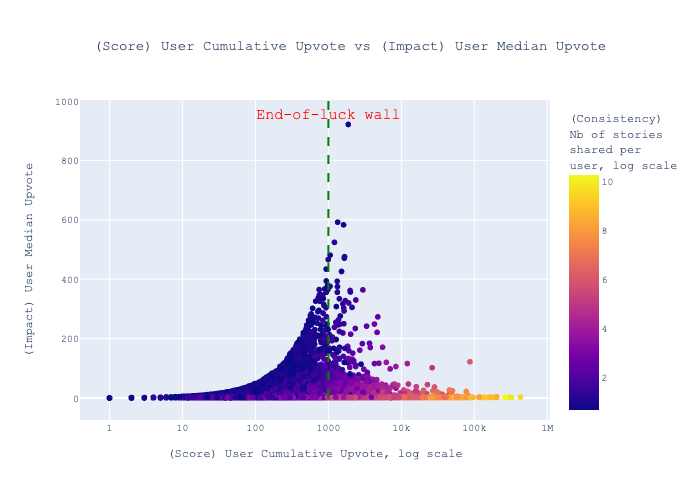
Here’s what we can discern:
- For scores up to approximately 1000:
- Users can initially boost their score by focusing on impactful stories.
- However, as scores increase with this strategy, the trend becomes less pronounced, hinting that chance plays a role (like being the first to break major news).
- There appears to be a threshold beyond which focusing solely on impact is less effective, leading to the next observation.
- For scores beyond 1000:
- Attaining higher scores, especially the top scores, is predominantly a result of sharing a higher number of stories.
Thus, the data supports the conclusion that for those aiming to “win” at HN, consistent story sharing is the most effective strategy.
Topics trend
In examining the progression of story topics on Hacker News, I analyzed the titles of stories to identify trends over time. The focus was on the ten most prevalent topics, as illustrated in the graph below.
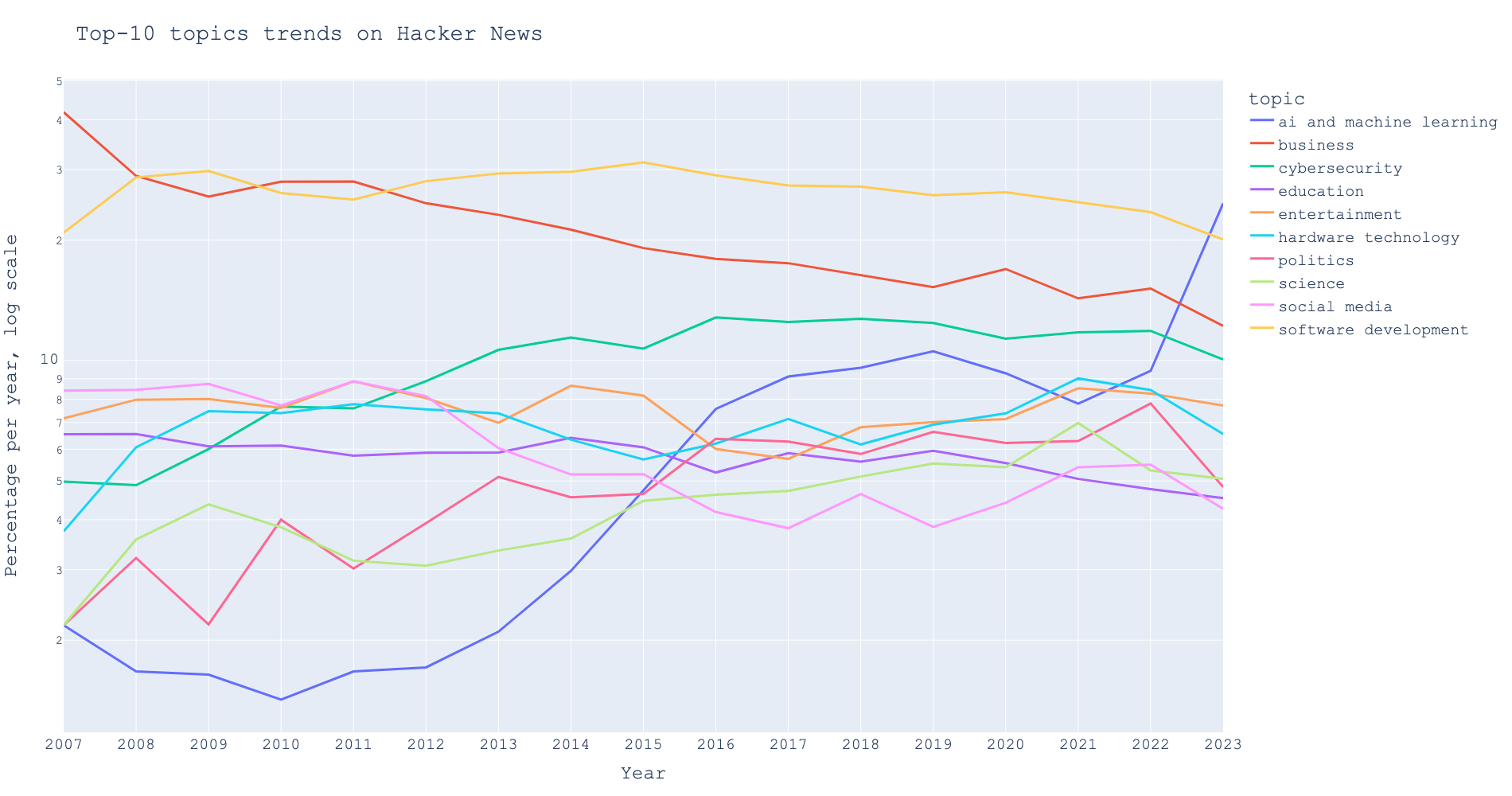
The data confirms that business has consistently been a leading subject of conversation since HN’s inception, alongside software development. However, there has been a noticeable shift: discussions on business have been waning, while interest in artificial intelligence and machine learning has surged dramatically, surpassing the former frontrunners in 2023.
Personal note: Why am I doing this?
Why am I delving into this project? It’s simple: these endeavors push my technical boundaries, from establishing databases and infrastructure to implementing analytics and scaling. At this magnitude, errors come at a high cost, and any less-than-optimal choices become a significant nuisance, slowing progress (a topic I might expand on in a future post).
I’m drawn to the dynamism of live data; it’s always current, always evolving, and it paves the way for intriguing projects, such as forecasting story trends. In contrast, static datasets on platforms like Kaggle can quickly become mundane.
My ambition extends to crafting a new interface for my personal use on top of HN. Currently, HN stories are primarily accessed through a single board view. Why not design a tailored recommendation engine to curate stories of interest to me? Or create a tool to track specific users and their story submissions? I believe HN has untapped potential waiting to be explored.
This journey has also led me to revisit historical content, offering me a fresh perspective. For instance:
- ColinWright was a standout contributor on HackerNews up until around 2015. I stumbled upon this fact while analyzing data spanning from 2006 to 2015. One of his shared analyses on HackerNews dynamics led me to his website, which, despite its minimalistic design, struck me as elegant and effective.
- I encountered old posts that left a lasting impression on me:
- The death of Aaron Swartz: I knew very little about Aaron when he was alive, and only few years ago I came to know more about him when I watched “The internet’s own boy” documentary about him. His story still resonates me, as I became more and more confident that there is no justice in this world, and that the law is nothing more than a tool for a few to keep the leash on the rest and maintain the status-quo.
One of this blog posts, “What happens to the Dark Knight”, still gives me a lot to think about.
Another person made a list of Aaron’s work to honor him. One of it was the
webpypython web framework, which was a nice discovery. I always wanted to learn what a web framework looks like under the hood. Flask or Django source code is much more complicated, butwebpyseems more feasible and approachable to learn. - A UX designer who learned how to build a web app using Python-Django back in 2011. Her website had a story about her personal business, and even though it was profitable, she decided to shut it down, and estimating the cost of the lost opportunity. This resonated with me, as I am considering going through a similar journey myself.
- By a coincidence, while looking at the data, I found that the story with
id=21is made bysama. I only know onesama, Sam Altman (OpenAI), which indeed turned out to be his account (apparently he is not active since ~3 years now). On the post, there is a comment frompg, which turned out to be Paul Graham. These are not earth shattering discoveries, probably irrelevant to anyone. But I love how looking at the data from a different point of view yielded such info.
- The death of Aaron Swartz: I knew very little about Aaron when he was alive, and only few years ago I came to know more about him when I watched “The internet’s own boy” documentary about him. His story still resonates me, as I became more and more confident that there is no justice in this world, and that the law is nothing more than a tool for a few to keep the leash on the rest and maintain the status-quo.
One of this blog posts, “What happens to the Dark Knight”, still gives me a lot to think about.
Another person made a list of Aaron’s work to honor him. One of it was the
Such discoveries are a testament to the power of perspective and the hidden gems it can reveal.
Notes on the analysis
Why I didn’t use the user’s karma?
I found multiple weird patterns in the user’s karma. For example, some users, who shared stories with large number of upvotes, had zero karma. Even more interestingly, there was negative karma. I don’t even know how this came to be.
| Karma level | Percentage |
|---|---|
| Positive | ~97.9 % |
| Zero | ~1 % |
| Negative | ~1.13 % |
Then, there are people who shared stories, with a median of more than one, yet, their karma is one (See the table below: Percentages, normalized by index)
| Karma < 0 | Karma > 0 | Karma == 0 | |
|---|---|---|---|
| Median < 5 | 1.21 | 97.72 | 1.07 |
| 5 < Median < 10 | 0.56 | 99 | 0.42 |
| Median > 10 | 0.24 | 99.66 | 0.10 |
I know what you might be thinking: these are low percentage of outliers. But this is what I found visually (the tables are just to communicate the observation).
It is very possible that this metric is tied to something else, like the upvotes on the user’s comments (this data is not available), or comments on their shared stories, or followups on the user’s comments.
All of this left me unsure about what the meaning of karma is exactly.
Update: This Wikipedia article clarified a bit more the dynamics of the karma.
However, unlike Reddit where new users can immediately both upvote and downvote content, Hacker News does not allow users to downvote content until they have accumulated 501 “karma” points. Karma points are calculated as the number of upvotes a given user’s content has received minus the number of downvotes.[2] “Flagging” comments, likewise, is not permitted until a user has 30 karma points.
This might explain things. Although I have a 30 karma points and I can’t flag comments, thus, suggesting there was a change to this system.
When calculating the user expected lifetime
When I made this analysis, I only took the “year” part of the first / last appearance dates for the users, to simplify my life. This means that:
- A user whose first appearance is 31/12/2011 and his last appearance is 01/01/2012 will be counted as active for a year
- A user whose first appearance is 01/01/2011 and his last appearance is 31/12/2011 will be counted as active for a year only as well.
- So, the true number here (of the expected user lifetime) is between 0~2 years.
User’s trend graph
I’ve also excluded the users who just appear in 2023, 2024, or last seen in 2024, as the year is far from over, and those it is not possible to make conclusions about it.
Topic modeling
I went all over the place with this one.
Recently I saw this post, where the authors analyzed the topics of OpenAI forums using Atlas Nomic. It looked impressive. But when I tried it myself (results here), I really didn’t like the extracted topics. It is always an issue for me with these unsupervised, generic techniques.
Then I followed a semi-traditional approach: In order to that, I made an initial list of the topics that I thought were relevant, annotated some data accordingly, reviewed the topics list, more annotation,…etc. That went back and forth many times until I settled on a list of topics that seemed satisfying enough. Afterwords, I relied on GPT-4 to get the topics for each of the story titles. Few rounds of cleaning afterwords, and that was the final outcome
There are limitations of this work though:
- The actual quality of the annotated topics is questionable. After all, what is the criteria of quality in this case?
- I decided on a single topic per story title. This is a major simplification.
- Relying on the story title to extract the topic is limiting, since it is just a sentence at best.
Acknowledgement
Many thanks to Tamara Persikova, Anya Ruvinskaya and Makia Zmitri for reviewing this work. Based on their comments, I rewrote most of this article around a more coherent structure (the draft I sent them was horrible 😅 ).